- Code de Huffman en C
- Partie 1 : Recherche bibliographique
- Partie 2 : Développement
- Partie 3 : Code source
I. La théorie de l’information
1. Présentation générale
Les systèmes de traitement de l’information ont toujours utilisé des techniques de codage, bien avant l’informatique : les différents systèmes d’écriture, le Braille, le Morse, la sténo. Avec la généralisation de la numérisation de l’information sous toutes ses formes, il existe maintenant une grande variété de codes, adaptés à ses divers supports de transmission et de stockage (câbles coaxiaux, ondes hertziennes, disques magnétiques, CD-ROM, DCC, etc.).

Les codes sont conçus, en plus de la simple représentation de l’information, pour satisfaire à certaines exigences sur l’information codée : réduire sa taille (c’est la compression de données ), la rendre incompréhensible par des tiers (c’est la cryptographie ), permettre de reconstituer l’information initiale, même si elle a été altérée par un bruit (c’est la correction d’erreurs ). Dans ce projet nous nous intéresseront au codage de Huffman qui est un code de compression non destructif c’est à dire que les données décodées sont identiques à celles codées.
2. Le Codage de Huffman
Le codage de Huffman est un algorithme de compression qui fut mis au point en 1952 par David Huffman. C’est une compression de type statistique qui grâce à une méthode d’arbre que nous allons détailler plus loin permet de coder les octets revenant le plus fréquemment avec un code de bit beaucoup plus court. Cet algorithme offre des taux de compression assez bons et est utilisé dans de nombreux formats de compression (zip, jpg).
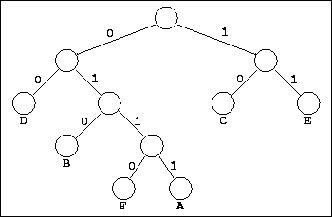
La compression de Huffman est un codage qui est une fonction inverse de la fréquence d’apparition. Plus un symbole apparaît et plus la longueur du code lui correspondant sera petite. En pratique on fait un tableau donnant le nombre d’apparition de chaque signe. On construit un arbre binaire en partant du bas. Les deux caractères les moins fréquents de la liste sont reliés à leurs parents en faisant la somme des comptes des fréquences. Les symboles prennent alors les valeurs 0 ou 1 qui sont retirées de la liste. Le processus est répété sur l’ensemble des caractères jusqu’à qu’il ne reste plus qu’un seul élément parent formant la racine de l’arbre. Pour décoder il suffit de redescendre et de noter les chemins parcourus pour arriver jusqu’aux feuilles et ainsi on obtient le caractère correspondant au code de Huffman. Une caractéristique essentielle du codage de Huffman est qu’il n’utilise pas de séparateur entre deux symboles. Chaque symbole est décodable de manière unique grâce à une technique de préfixe, c’est-à-dire si aucun mot du code n’est le préfixe d’un autre mot du code (par exemple 01 étant préfixe de 0111, ces deux mots ne peuvent appartenir à un code préfixe).
Cette méthode donne de bons résultats, mais souffre de quelques limites qui ont amené à le faire évoluer. Les contraintes sont :
- lecture préalable de l’ensemble des données
- construction de l’arbre binaire
- impossibilité de comprimer des données non connues à l’avance (page à « faxer »)
- transmission des codes employés pour la compression (le décompresseur doit connaître l’arbre pour reconstituer les données initiales)
Ces problèmes entraînent une perte de vitesse dans la compression et/ou la transmission et une dégradation du ratio de compression global.
Des solutions ont été envisagées pour améliorer les performances :
- construction d’un arbre de Huffman définitif (par exemple, on connaît les fréquences d’apparition des lettres de l’alphabet dans les textes en français)
- codage de Huffman dynamique (on construit un arbre à partir de répartitions théoriques des fréquences et on effectue une mise à jour dynamique au fur et à mesure que les informations sont traitées)
Remarque : le codage de Huffman est inutile lorsque tous les caractères sont équiprobables.

II. La théorie de la programmation
1. Principe de l’algorithme
L’algorithme de Huffman peut pour la compression peut être décomposé en cinq étapes distinctes :
- Faire la liste des symboles et les trier par nombre d’occurrences croissantes ; ces symboles constituent les feuilles de l’arbre de Huffman.
- Prendre les deux nœuds de plus faible occurrence, les combiner en faire un nœud dont l’occurrence est égale à la somme des deux occurrences et marquer les nœuds fusionnés par 0 pour le premier et 1 pour le second (par ordre de probabilités décroissantes). Le nouveau nœud crée comportera les adresses les adresses des nœuds fils.
- Répéter l’étape (2) jusqu’à ce qu’il ne reste qu’un seul nœud qui devient la racine de l’arbre binaire ainsi constitué.
- Parcourir l’arbre depuis la racine jusqu’aux feuilles afin de déterminer les code de Huffman pour chaque caractère.
- Lire le fichier à compresser en remplaçant chaque caractère par son codage de Huffman.
2. La construction de l’arbre
Une fois que les occurrences de chaque caractère présent dans les fichiers ont été déterminées, il faut construire l’arbre de Huffman. Pour cela on trie les caractères par occurrences et on crée un nœud qui pointe vers les deux plus petites. On insère ce nouveau nœud dans la liste avec comme occurrence la somme des occurrences des feuilles qu’il remplace. On répète l’opération jusqu’en avoir plus qu’un seul.
3. La compression
L’archive compressée se compose de 2 parties distinctes :
- L’en-tête : contient toutes les données nécessaires à la décompression du fichier ainsi que des informations sur le fichier.
- Les données : correspond à la transcription en symboles du fichier à compresser.
Durant cette phase les octets du fichier initial seront remplacés par leur code de Huffman correspondant.
4. La décompression
La décompression de fait en 2 étapes :
- Dans un premier temps on extrait les informations contenues dans ‘en-tête afin de pouvoir reconstituer l’arbre qui a servi à la compression. (En cas de différence entre les arbres la décompression est impossible).
- Une fois l’arbre reconstitué on effectue un décodage bit à bit du fichier.
Le décodage d’un code préfixé se fait à l’aide d’un arbre. Il suffit de lire les symboles successifs du texte codé : si c’est un 0, on suit la branche de gauche, si c’est un 1, celle de droite ; quand on arrive à une feuille de l’arbre, on a décodé une lettre de la source ; on remonte alors à la racine et on continue avec le symbole binaire suivant. Il n’est pas nécessaire d’introduire un séparateur ou de décomposer en symboles.
Bonsoir,
J’ai un projet sur l’algorithme d’huffman (uniquement la partie compression) à rendre avant le 28/02/2014 et je suis un « cancre » en informatique mais j’essaie de comprendre ce que vous avez fait là sur ce projet!!
D’abord merci d’avoir rendu public votre projet, étant en premier année d’école d’ingénieur je compte prendre exemple mais par la suite j’aimerais savoir si c’est possible que vous puissiez m’aider dans mon projet (éventuellement une rémunération si vous le voulez)?
Cordialement
Bonjour,
Il faudrait m’en dire plus sur votre projet. Quelles sont les fonctionnalités qui doivent être mises en place dans le programme ? Celui disponible à la fin de cet article contient plusieurs fonctions qui ne seront pas forcément nécessaires dans votre cas. Par exemple :
– Sauvegarde d’un fichier texte avec le codage utilisé pour chaque caractère
– Sauvegarde d’un fichier texte qui stocke pour chaque caractère le nombre fois où il est présent dans le fichier
– La compression et la décompression de tous les fichiers d’un répertoire (sans récursivité, on se limite au 1er niveau uniquement).
En fonction de ce que vous souhaitez utiliser, il sera possible de réduire le code pour ne garder que les fonctions utilisées. Dans cette étape je pourrais vous aider.
bonjour, voici mon projet en question , il n’est pas long (que la compression), de plus j’ai déjà fait la partie A.
–http://moodle.ensea.fr/pluginfile.php/*******/S2_SD_2013-2014_TP03.pdf
Bonjour,
Moi je travaille sur un projet utilisant le codage de Huffman dans la compression JPEG.
Votre projet m’a beaucoup aidé, merci beaucoup et bon courage.
Bonjour Yannick,
Merci pour votre message. Si ce programme peut encore aider des personnes dans leurs développements, ça me fait plaisir. Surtout quand je pense que ça va faire maintenant 10 ans qu’il a été écrit. J’ai été regardé par curiosité comment fonctionnait la compression JPEG et c’est bien plus compliqué que le simple programme de Huffman ! Bon courage à vous !
Hey ! Votre projet m’a beaucoup aidé.
J’ai aussi un projet à faire sur Huffman. Et j’ai besoin d’aide :
Je dois à partir d’un fichier texte :
– Calculer la probabilité de chaque lettre de l’alphabet dans ce fichier.
– Construire la table de code pour l’encodage Huffman
– Générer le fichier compressé (un .txt) (où il y a que des chiffres dedans) et montrer le ratio de compression.
– Et montrer que le fichier décodé de Huffman est égal au fichier original
Merci d’avance
Bonjour Wolf,
Je suis content que ce projet soit encore utile aujourd’hui. Je vais essayer de répondre à vos quatre questions. Je pense vraiment qu’il ne faut pas chercher à faire compliqué.
1. La probabilité d’une lettre est égale au nombre de fois où elle apparait / Nombre de lettres total du fichier. Comme pour votre projet, le mien a été écrit dans un but pédagogique. Il produit une fichier -frequence.dat qui contient pour chacune des lettres le nombre de fois où elle est présente. Il serait simple d’ajouter une colonne supplémentaire à ce fichier pour afficher la probabilité en divisant le nombre d’occurrences par le nombre total de caractères.
2. La table de code est en fait l’arbre binaire. Elle est par la suite enregistrée dans le fichier compressé afin d’être utilisée pour pouvoir décompresser l’archive. Les codes utilisés pour chacune des lettres sont enregistrés dans le fichier -codage.txt produit lors de la compression.
3. Ration de compression = Taille avant compression / Taille de l’archive. Vous pouvez facilement obtenir ces informations avec le gestionnaire de fichier. Un point important à prendre à en compte est que l’arbre est stocké dans l’archive et représente environ 1ko. Donc pour les très petits fichiers, le ratio de compression sera nul voire négatif. Pour obtenir une idée sur les capacités de compression du programme, les fichiers doivent avoir une certaine taille.
4. Il existe des utilitaires qui permettent de comparer les fichiers. Sur Unix il y a diff qui compare même les fichiers binaires. Sur Windows je n’en connais pas mais ça doit exister. La confirmation avec un logiciel externe au projet apportera également une garantie sur le bon fonctionnement du logiciel.
Bon courage !