Les recommandations du W3C
Il est fréquent de rencontrer des pages présentant des problèmes d’affichage sur un navigateur alors que sur un autre elle s’affichera sans problèmes. Les causes de ces problèmes sont que lors des débuts d’internet, les développeurs de navigateurs ont crées des extensions HTML propriétaires ne pouvant être affichées que par leurs navigateurs respectifs.
En 1994 le W3C (World Wide Web Consortium) a été fondé pour promouvoir la compatibilité des technologies d’internet. Les avantages d’une standardisation sont nombreux :
- La portabilité : Chaque utilisateur doit être libre d’utiliser le navigateur de son choix. Les sites réalisés en suivant ces standards seront interprétés de la même manière quel que soit le moyen par lequel on y accède. La standardisation favorise également l’échange de données entre divers environnements.
- Les CSS : Les feuilles de style en cascade sont utilisées pour décrire la présentation d’un document écrit en HTML. Elles sont utilisées pour définir les polices, les couleurs, le rendu et d’autres caractéristiques liées à la présentation. L’objectif est de bien séparer la structure du contenu. (voir paragraphe Séparation du contenu et de la forme).
- Réduction du volume des données : L’utilisation de CSS pour la mise en page des documents réduit de 25% à 50% la taille des données échangées.
- Amélioration du référencement : Des documents conformes aux standards sont plus facilement indexés. En repérant la structure les moteurs de recherche peuvent indexer précisément le contenu.
Le W3C met à disposition un outil permettant de savoir si une page est aux normes. Si la page passe le test avec succès l’organisme met à disposition du webmaster un logo. En l’affichant sur le site, il montre que lors de sa création le webmaster s’est attaché à respecter les recommandations. Sur le site chacune des pages a été validée ainsi que la feuille de style les logos sont affichés dans la partie « mentions légales ».
![]()
Le langage HTML
Le site remis à l’entreprise est composé de trois langages différents. Chacun de ces langages a une fonction particulière.
HTML (Hypertext Markup Langage) est un langage de mise en page de documents à l’aide de balises. Les documents HTML sont identifiés par une adresse URL, et sont interprétés par un navigateur web. Les pages HTML apparaissent à l’écran de la manière dont l’auteur l’a voulu mais elles ne peuvent pas contenir d’instructions exécutables.
Le langage PHP
PHP (PHP Hypertext Preprocessor) est un langage de script exécuté coté serveur. Sa syntaxe est proche du langage C. Il peut être soit inséré directement dans du code HTML soit écrit dans un fichier à part et appelé à l’aide de la fonction include ou require. Ces fichiers portent une extension .php Il permet de générer des pages web au contenu dynamique. Lorsqu’un visiteur demander à consulter une page, son navigateur envoie une requête au serveur HTTP. Si la page contient du code PHP, l’interpréteur du serveur exécute ce code et renvoie le code HTML généré. PHP possède des fonctions qui permettent la gestion des bases de données MySQL. A aucun moment le visiteur ne peut voir le code PHP.
MySQL
Il s’agit d’un système de gestion de bases de données (SGBD). La version disponible sur le serveur web est la 4. MySQL est sous licence GPL. Ce qui signifie qu’il peut être utilisé gratuitement. PhpMyAdmin est une application écrite en PHP et permet l’administration des bases MySQL. Elle doit être placée sur le site. Il est possible de créer des tables, d’en visualiser le contenu, d’exécuter des requêtes et d’exporter le contenu de la base. Cet outil a été utilisé dans la création et pour les tests des bases mais n’a plus d’utilité dans l’utilisation quotidienne du site par l’entreprise.
Le JavaScript
Le code JavaScript est inséré directement dans les pages web ou dans un fichier séparé mais contrairement à PHP il est exécuté par le navigateur sur le poste client. Le temps de latence est donc presque nul puisqu’il n’y a pas d’échange de données avec le serveur. Toutefois ce langage présente des problèmes de portabilité entre les différents navigateurs ce qui m’a poussé à restreindre son utilisation au contrôle des données saisies par l’utilisateur.
Le site Internet
Dans un premier temps, il m’a fallu déterminer l’architecture du site, c’est à dire la façon dont seraient liées les pages entre elles. Il est important de faire un site le plus intuitif possible pour que le visiteur ne cherche pas son information et ne se perde pas. Chaque page doit être atteinte en effectuant le moins de clics possible. Plusieurs modèles ont été réalisés afin de déterminer celui qui correspondait le mieux au résultat souhaité. L’utilisation d’un menu latéral semblait la meilleure solution. L’espace en dessous des boutons du menu pourrait servir dans l’avenir à faire défiler des informations relatives à l’entreprise.

La mise en page en HTML dans les grandes lignes a été faite avec NVU. A l’aide de l’interface graphique du programme il est possible de créer des tableaux, du texte, des liens ou d’insérer des images.
Comme il s’agit d’un logiciel très récent j’ai rencontré beaucoup de bugs notamment dans l’ajustement des tableaux et dans le changement des polices. En regardant de plus près le code produit, je me suis aperçu qu’il était composé d’un grand nombre de balises superflues et qu’il ne correspondait pas aux recommandations du W3C. Ceci s’explique par le fait que NVU ne travaille pas à partir de la source HTML mais uniquement à partir du rendu graphique (la source est crée en fonction de l’affichage et non l’inverse ou les deux ensemble). Une modification hasardeuse du code source directement à partir du NVU peut entraîner une erreur du programme et la perte des données depuis le dernier enregistrement. De plus en cas d’ouverture d’un fichier produit par un autre éditeur la source est modifiée ainsi que l’indentation. Il est de cette manière impossible de retravailler un fichier réalisé sous une autre application. Un autre problème de NVU est qu’il ne gère pas le PHP dans ses pages. Il est possible d’en insérer quelques lignes mais développer un site entier n’est pas faisable.
J’ai utilisé NVU dans la première élaboration des pages, principalement pour la mise en page en utilisant les tableaux. Une fois que le squelette de la page a été créé, il a fallu le retravailler avec Notepad++ pour le nettoyer des balises superflues et y rajouter le code PHP. Une fois que les modifications ont commencé, il n’est plus possible de repasser sous NVU sans risquer de perdre une partie des données.
Le graphisme et la retouche sont deux domaines dans lesquels, malgré ma bonne volonté, je manque d’inspiration et de formation. C’est pour cette raison que la mise en page est assez austère. J’ai rajouté quelques effets utilisant des méthodes simples. Un effet roll-up lorsque la souris passe au-dessus afin de rendre la présentation plus animée. Il s’agit des fonctions de Dreamwaver utilisant JavaScript que j’ai récupéré sur un forum puis insérer dans la source. Les deuxièmes boutons sont chargés en même temps que la page afin d’être opérationnels de suite. Plusieurs bannières en-tête ont été également crées et sont nommées de la manière suivante : bannière-numéro.jpg la fonction rand() de PHP en choisi une au hasard ce qui contribue animer le site.
Les CSS : Séparation du contenu et de la forme
Le langage HTML décrit l’architecture du document et CSS définit la mise en page. La séparation du contenu et de la forme offre plusieurs avantages sur la maintenance du code et sur le temps de chargement :
- La feuille de style est dans un fichier séparé. Elle est chargée lors de l’affichage de la première page. Elle est ensuite stockée dans le cache du navigateur.
- La conception des pages se fait en deux étapes. La structure HTML et la présentation CSS. Il est ainsi aisé de modifier la charte graphique sans toucher au code. Sans l’utilisation de CSS chaque balise doit être modifiée séparément.
- Plusieurs feuilles de style peuvent être définies pour un même document pour une mise en page personnalisée.
- Le code HTML est réduit en taille et en complexité. Il est ainsi possible de séparer les tâches entre les graphistes et les développeurs.
La feuille de style du site a été réalisée lors de la dernière semaine. Une fois que je m’étais assuré qu’il n’y avait plus de problèmes de structure et que la mise en page avait été validée par l’entreprise. Lors de la création il faut s’assurer à penser à mettre les balises qui permettront d’appliquer ces règles d’affichage (titres, cellules, liens…).

Sans l’utilisation de CSS, ces propriétés doivent être rentrées pour chaque tableau différents dans chaque balise <table>. De cette manière en écrivant <table class= ”categorie”> les propriétés pré-définies s’appliquent. On voit bien que le code est nettement moins chargé et que la modification de ces quelques lignes met à jour tout le site. Il peut être envisageable de créer plusieurs CSS pour le site et ainsi de changer régulièrement la présentation.
Le référencement
Le référencement a été fait une fois que le site a été terminé pour ne pas référencer des pages qui n’existeront plus. Les pages contiennent des informations pour permettre aux moteurs de recherche de référencer correctement le site. Ces informations se trouvent dans des balises META situées dans la balise HEAD des pages HTML, juste après la balise TITLE. A l’intérieur de ces balises on trouve des informations sur la page. Ces informations ne sont pas destinées aux utilisateurs mais aux moteurs de recherche. Les moteurs de recherche s’en servent (de moins en moins) lors du référencement des pages. Les balises META utilisées par les moteurs de recherche sont :
- META NAME = “keywords” CONTENT = “…” permet d’ajouter des mots clés sans surcharger les pages. Ils améliorent le classement de la page pour ces mots.
- META NAME = “description“ CONTENT = “…“ permet d’indiquer en une phrase de décrire le contenu de la page. Cette phrase peut apparaître dans le résultat d’une recherche.
- NAME = “Robots“ indique aux moteurs de recherche le chemin à suivre et les zones à ne pas indexer. Ces informations relatives aux zones à ne pas indexer sont inscrites dans le fichier robots.txt situé à la racine du site.
Il est également possible de spécifier la langue dans laquelle est écrit le site (utile pour restreindre les recherches en français), des informations sur les logiciels utilisés pour la création ou le nom et les coordonnées du webmaster. Ces renseignements sont sans utilité pour le fonctionnement du site. Ils n’ont pas été renseignés.

La première étape consistait à enregistrer le site sur le plus de moteurs possible. Cette opération se fait directement à partir de l’adresse de celui-ci.
La méthode principale utilisée par Google est le PageRank. Elle mesure la popularité des pages en fonction du nombre de liens pointant vers celles-ci. Google associe les mots du lien à la page pointée. Plus le PageRank de la page qui comporte le lien est élevé et plus le lien aura une haute valeur dans le calcul. Il fallait donc que d’autres sites pointent vers l’adresse du site. Le site a ensuite été enregistré sur différents annuaires dans la catégories appropriée. La popularité se mesurant au nombre de liens il est présent dans des annuaires n’ayant aucun rapport avec la publicité.
La console d’administration du site
Fonctionnement du catalogue
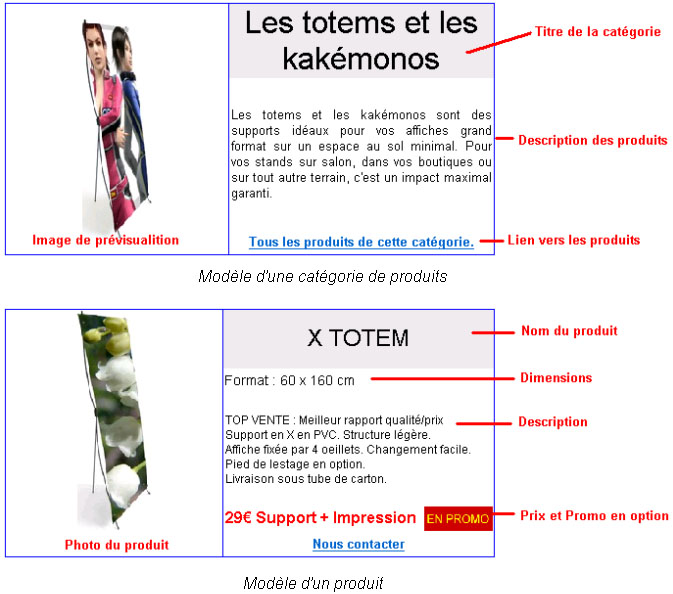
Les produits sont regroupés en catégories. A chaque produit peut être rattaché une ou plusieurs images. L’ajout de nouveaux produits et la mise à jour du site devra permettre d’organiser le catalogue
La maintenance d’un site Internet requiert des compétences en informatique. L’entreprise a besoin de mettre à jour et modifier son site régulièrement. Comme aucun employé n’a de connaissances dans ce domaine une procédure simplifiée et rapide doit être mise en place. J’ai développé une partie du site entièrement dynamique en PHP. Cette interface permet de remplir des champs d’une base de données MySQL avec les renseignements des produits.
Dans un premier temps il a fallu trouver des champs et une mise page qui fonctionneraient pour tous les produits. Ensuite plusieurs modèles de mise en page ont été élaborés pour finalement en retenir un. Il aurait été intéressant de poursuivre le développement en intégrant différents modèles de mise en page afin de mettre en valeur certains produits.
Définir un accès restreint
La mise à jour du site s’effectue en ligne au travers de formulaires. L’accès se fait à partir d’une page hébergée sur le site. Même si aucun lien ne dirige vers cette page, il est indispensable d’autoriser l’accès uniquement aux utilisateurs habilités à modifier le site. Il existe plusieurs méthodes pour sécuriser des pages d’un site :
- Installer un système de cryptage asymétrique avec le protocole SSL.
- Utiliser les variables $_SESSION et $_COOKIE de PHP pour stocker les identifiants de l’utilisateur.
- Utiliser les fichiers .htaccess et .htpasswd disponibles sur les serveurs Apache.
Les hébergements mutualisés ne permettent pas la mise en place du cryptage SSL. Et l’utilisation du site ne nécessite pas une très grande sécurite.
L’utilisation des sessions permet à l’utilisateur de s’identifier directement à partir d’un formulaire dans la page. Une fois les champs remplis, il faut comparer avec une base de données contenant les informations de connexions pour chaque utilisateur puis stocker un identifiant de session unique dans un cookie chez le client.
J’ai finalement décidé d’employé la méthode des fichiers .htaccess et .htpasswd pour sa simplicité de mise en place. Ces deux fichiers contiennent des commandes Apache. Le fichier .htpasswd contient les mots de passe et le fichiers .htaccess se place à la racine du répertoire à sécuriser.
Le fichier .htpasswd contient sur chaque ligne le nom d’utilisateur suivi du mot de passe crypté. Ce fichier doit être placé de préférence dans un endroit du site non accessible à l’aide de protocole HTTP afin de réduire sa visibilité le plus possible. Le cryptage du mot de passe est irréversible : il n’est pas possible de décrypter un mot de passe. Le cryptage a été réalisé à l’aide d’un utilitaire mis à disposition par OVH.
La procédure d’identification se fait en cryptant le mot de passe saisi par l’internaute et en le comparant à celui contenu dans le fichier .htpasswd. Voici le fichier .htpasswd utilisé. Les deux premiers caractères correspondent à la clé de cryptage qui devra être utilisée lors du cryptage du mot de passe entré.
![]()
Le fichier .htaccess défini les répertoires (et les sous répertoires) protégés par le fichier .htpasswd. Ce fichier contient des commandes Apache qui seront interprétées par le serveur web.

L’enregistrement de nouveaux produits
Une fois l’identification réussie, la page d’accueil du portail s’affiche avec les différentes possibilités de gestion qu’offre le site. Cette partie du site a été développée entièrement en PHP. Le menu sur la gauche de l’écran récapitule les possibilités de gestion et de mise à jour offertes.
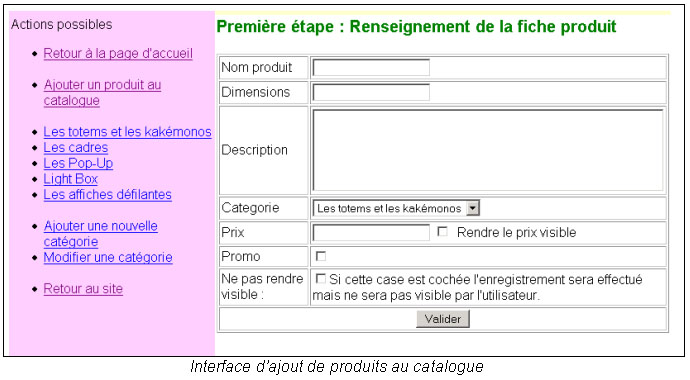
Dans un premier temps, il faut remplir les champs du formulaire. Certains champs sont obligatoires. L’utilisateur renseigne les informations qu’il souhaite voir affichées. Les cases à cocher permettent de régler des options d’affichage. La case « Ne pas rendre visible » offre la possibilité de rajouter des produits en prévisions d’une mise en ligne future sans les afficher sur le site.
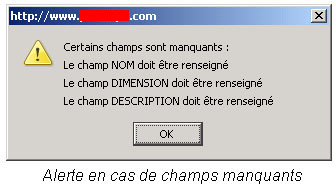
Après le validation, un premier contrôle est effectué directement par le navigateur à l’aide d’un JavaScript. Les champs sont contrôlés une deuxième fois sur le serveur dans du code PHP.
La deuxième étape de l’ajout d’un produit est l’association avec les images. Une boîte de dialogue permet à l’utilisateur de parcourir son disque à la recherche de la bonne image. Chaque produit peut être associé à plusieurs images. Une fois que les images sont chargées sur le serveur, elles sont renommées de manière à éviter les doublons avec une image d’un autre produit portant le même nom.
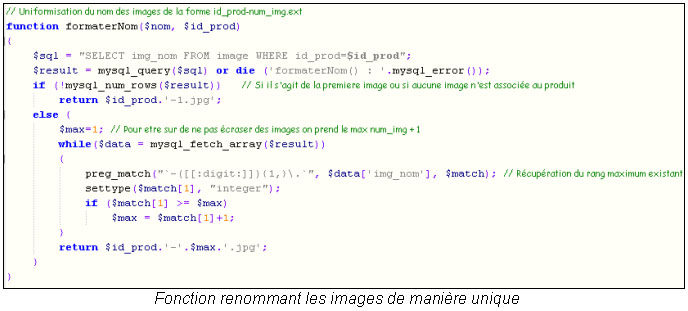
Dans la première version du site, les images étaient stockées directement dans la base. En raison de la limitation de la taille des bases à 40Mo, seule l’adresse de l’image est maintenant stockée, l’image est dans un répertoire particulier du serveur. Ce changement m’a obligé à renommer chaque image de manière unique. La combinaison est le numéro du produit suivi du numéro de l’image Voici un enregistrement dans la table IMAGE.

Comme plusieurs images peuvent être associées à un seul produit, il faut en choisir une qui s’affichera sur le site. Les autres images seront enregistrées pour permettre de changer de visuel de manière simplifiée. A l’origine le fait de pouvoir associer plusieurs images devait servir à faire un diaporama pour chaque produit.
La modification des produits
Dans le menu, toutes les catégories de produits sont listées. En cliquant sur l’une d’elle on obtient un aperçu des produits par catégorie tels qu’ils sont visibles sur le site. A partir de cette liste il est possible de modifier le contenu du site sans toucher au code HTML. En plus de pouvoir modifier le contenu, il est possible de modifier l’ordre d’affichage afin de mettre en évidence certains produits.
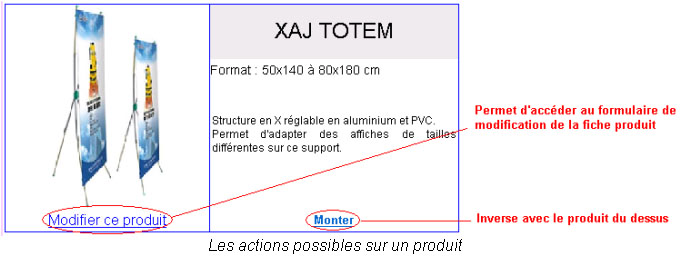
En cliquant sur « Modifier ce produit » on accède sur un formulaire qui reprend les informations relatives au produit. Il est également possible de modifier ou supprimer des images qui s’y rattachent.
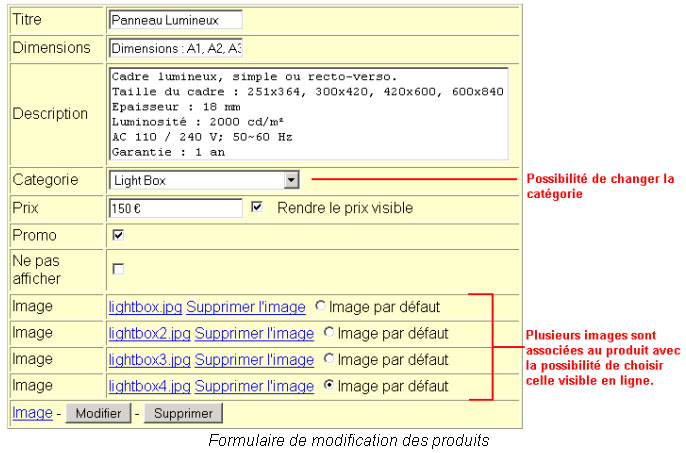
La gestion des images est la partie la plus compliquée à programmer. Tout d’abord il faut contrôler que le transfert jusqu’au serveur de passe sans erreur. Ensuite il faut renommer et transférer l’image dans le bon répertoire. Enfin il reste à enregistrer l’adresse dans la base. La gestion de « Image par défaut » se fait grâce à un champ dans la base IMAGE. Ce champ peut être fréquemment amené à évoluer en fonction de l’ajout et de la suppression des images. En cas de suppression de l’image principale une autre image est choisie et une alerte informe qu’il s’agissait de l’image visible. Cette image est choisie arbitrairement. Si aucune image n’est associée à un produit, une image spéciale est affichée afin de ne pas perturber l’exécution du script d’affichage de la page.
Les catégories de produits
Chaque produit doit être rattaché à une seule catégorie afin de permettre un affichage sur le site. La création et la maintenance des catégories fonctionnent sur le même principe que pour les produits.
Les options d’affichages d’une catégorie influent sur tous les produits qu’elle contient. Par conséquent, si on choisit de ne pas afficher une catégorie les produits qui s’y rattachent ne seront pas visibles.
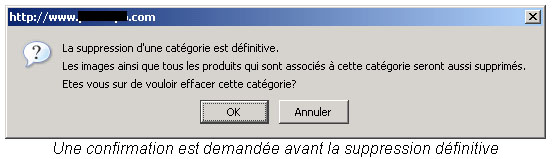
En cas de suppression de la catégorie, la description et l’image seront supprimées du serveur. Toutes les produits ainsi que les images qu’ils contiennent seront également supprimés après confirmation.
La plate-forme d’envoi d’emails
La classe PHPMailer
L’envoi d’emails utilise la classe PHPMailer. C’est une classe PHP qui permet d’envoyer des emails dans plusieurs formats à partir d’un script PHP. Deux méthodes d’envoi sont possibles :
- La méthode SMTP permet de se connecter à un serveur mail distant
- La méthode mail si le serveur mail est local.
Pour installer cette classe sur, il faut la télécharger et décompresser les fichiers dans un répertoires du serveur. Elle doit être appelée au début du script en utilisant le chemin réel sur le serveur :
![]()
Dans un premier temps, j’ai utilisé la méthode mail qui utilise la fonction mail() de PHP. Lors des tests cette méthode ne semblait pas provoquer d’erreurs. Toutefois lors du premier envoi en nombre sur une liste de diffusion un pourcentage anormalement élevé de messages été reconnu comme étant du spam et renvoyé à l’expéditeur. En testant cette méthode sur différentes adresses emails personnelles le message n’arrivait pas et aucun message d’erreur ne me revenait. Les messages devaient être détruit directement. Les emails crées avec PHP sont automatiquement détruits par la plupart de hébergeur gratuits sans se donner la peine de répondre car cette méthode très simple d’envoi a été utilisée dans l’envoi de spam. De plus il est impossible de contrôler l’identité de l’émetteur.
L’analyse de l’en-tête du message m’a donné des pistes sur ce que pouvaient être les sources de l’erreur. Afin de poursuivre mon analyse j’ai utilisé la deuxième méthode de la classe : la méthode SMTP. Cette méthode a un fonctionnement complètement différent de l’autre. Une connexion est établie avec le serveur mail et les données sont transmises suivant le protocole SMTP. Il faut compléter les champs Nom d’utilisateur et Mot de passe d’une adresse email existante sur le domaine yyyyyyyyyyy.com.
La procédure d’envoi
L’envoi d’un mailing se fait en trois étapes indépendantes :
- L’ajout d’informations sur les destinataires (email, nom, société).
- Le contenu du message.
- L’envoi du message en associant une liste avec un message.
L’enregistrement dans la base de données peut être effectué de trois façons différentes :
- Un fichier CSV (email, nom, societe).
- Un fichier texte en désordre contenant des adresses emails.
- En saisissant manuellement chaque adresse.
Les fichiers CSV peuvent être produits par le logiciel ACT avec lequel l’entreprise gère ses clients. Ainsi chaque client pourra recevoir un email avec son nom et sa société pour augmenter l’impact du message.
L’autre source d’adresses provient de fichiers scannés avec une reconnaissance d’écriture. Le contenu de ces fichiers n’est pas exploitable directement. Lors du chargement du fichier dans la base, le fichier est parcouru et les emails sont extraits à l’aide d’une expression régulière.

La gestion manuelle des adresses sert uniquement à rajouter des modifications ou compléter les adresses. Elle n’a pas été crée pour remplir la totalité d’une liste.

Le désabonnement
Conformément à l’article 34 de la loi « Informatique et Liberté » du 6 janvier 1978, le destinataire dispose d’un droit d’accès et de modification des données le concernant. Afin d’être en conformité avec les règles de la CNIL (Commission Nationale Informatique et Libertés) chaque email comporte un lien de désabonnement qui efface l’adresse de toute les listes de diffusion. L’entreprise est également informée par email lorsqu’un désabonnement se produit.